Challenges de Cryptopals
Dates du projet: 21 avril 2020 - Toujours en développement
Pour commencer à prendre contact avec la cryptographie, on m’a conseillé de commencer par ces challenges de Cryptopals, qui restent toujours d’actualité. Ils mettent l’accent sur la découverte d’algorithme de chiffrements (mise en place de leur implémentation par nos propres moyens) et également les attaques actuelles sur ces algorithmes. J’ai découvert qu’il y avait bien plus d’attaques possibles sur des algorithmes toujours utilisés, et que la majorité des failles venaient de leur utilisation, coté serveur notamment.
Beaucoup de solutions sont disponibles sur internet (en cherchant le titre des challenges) mais j’ai tenté de ne jamais chercher les solutions. Après avoir fini ce projet, il sera intéressant de comparer mon implémentation avec d’autres solutions, afin de perfectionner mon traitement algorithmique des problèmes.
Python est selon moi le langage idéal pour ce projet car il permet de prototyper très rapidement, sans se soucier du typage ou du contrôle d’erreur. Pour du code n’étant pas utilisé en dehors de ce projet, ce n’est pas un problème. Associé à l’outil Jupyter Notebook, j’obtiens un fichier structuré, alternant entre texte et code, avec la possibilité d’exécuter des blocs de code indépendamment des autres, afin de ne pas exécuter de nouveau des traitements lourds par exemple, ou re générer une clé secrète. Néanmoins, après avoir compris la partie algorithme, il sera intéressant de peaufiner le code, voire de passer à un langage plus structuré ou bas niveau, comme Rust ou C.
Le but de ce projet était de pouvoir m’accrocher à un projet personnel, donc de le rendre utile et de l’intégrer à mon cursus. Il n’est pas facile de se trouver face à ce type de challenge, sans indication et connaissance. Pourtant, j’ai le sentiment que les challenges de Cryptopals m’ont mis “le pied à l’étrier” et m’ont donné une connaissance préliminaire du domaine. Certains challenges ne sont pas particulièrement faciles, autant au niveau technique qu’au niveau de l’énoncé, mais la détermination et l’envie de comprendre m’ont poussé à continuer de chercher par moi-même.
Extraits de code
Analyse de texte
def get_chi2(text):
english_freq = {
'a':0.08167,
'b':0.01492,
'c':0.02782,
'd':0.04253,
'e':0.12702,
'f':0.02228,
'g':0.02015,
'h':0.06094,
'i':0.06966,
'j':0.00153,
'k':0.00772,
'l':0.04025,
'm':0.02406,
'n':0.06749,
'o':0.07507,
'p':0.01929,
'q':0.00095,
'r':0.05987,
's':0.06327,
't':0.09056,
'u':0.02758,
'v':0.00978,
'w':0.02360,
'x':0.00150,
'y':0.01974,
'z':0.00074
}
ignored = 0
count = {}
for c in text:
c = c.lower()
if c in english_freq:
if c not in count:
count[c] = 1
else:
count[c] = count[c]+1
else:
ignored+=1
chi_2 = 0
lenght = len(text) - ignored
if lenght<(len(text)//2):
return 1000
for (key,value) in count.items():
observed = value
expected = lenght*english_freq[key]
difference = observed - expected
chi_2+= difference*difference/expected
return chi_2Les premiers challenges se basent sur le chiffrement de César et celui de Vigenère en utilisant l’opérateur XOR. Trouver la clé secrète pour ces systèmes se résume à essayer de repérer la lettre la plus fréquente dans le texte chiffré, et d’émettre une supposition quant à la valeur de cette lettre dans le texte en clair, grâce à l’analyse fréquentielle. Si la supposition est correcte, la clé est trouvée. Néanmoins, pour valider une supposition, il faut pouvoir estimer si le texte “déchiffré” ressemble à un texte lisible (ici en anglais).
Après avoir abandonné l’idée de le faire à la main, j’ai cherché une manière simple d’estimer si un texte donné ressemblait à de l’anglais. J’ai fini par adopter le Pearson’s chi-squared test appliqué à la fréquence d’apparition des lettres de l’alphabet dans un texte en anglais. (Le pseudo code a été trouvé via stackoverflow). Cependant, le code d’origine a été modifié pour éviter les “faux positifs” : des textes avec un bon score qui ne sont pas du tout de l’anglais.
Les faux positifs sont majoritairement créés par du texte contenant peu de lettres de l’alphabet, et beaucoup de ponctuations ou autres caractères existants. Le calcul du score élimine les caractères non alphabétiques, ce qui aboutit à un très faible nombre de caractères retenus. Pour régler ce problème, j’ai déterminé arbitrairement que si le nombre de caractères retenus était inférieur à la moitié de la longueur totale du texte, alors l’algorithme retourne un score de 1000 directement.
Pour utiliser l’algorithme, j’établis un score maximum, et je ne garde que les textes ayant un score inférieur à ce maximum. Je peux ainsi moduler la sensibilité de la détection selon ce maximum.
Cet exemple montre parfaitement l’intérêt de la cryptographie à s’associer à d’autres disciplines comme l’IA appliquée à la reconnaissance de textes, avec des méthodes bien plus efficaces que la comparaison des fréquences.
Oracle
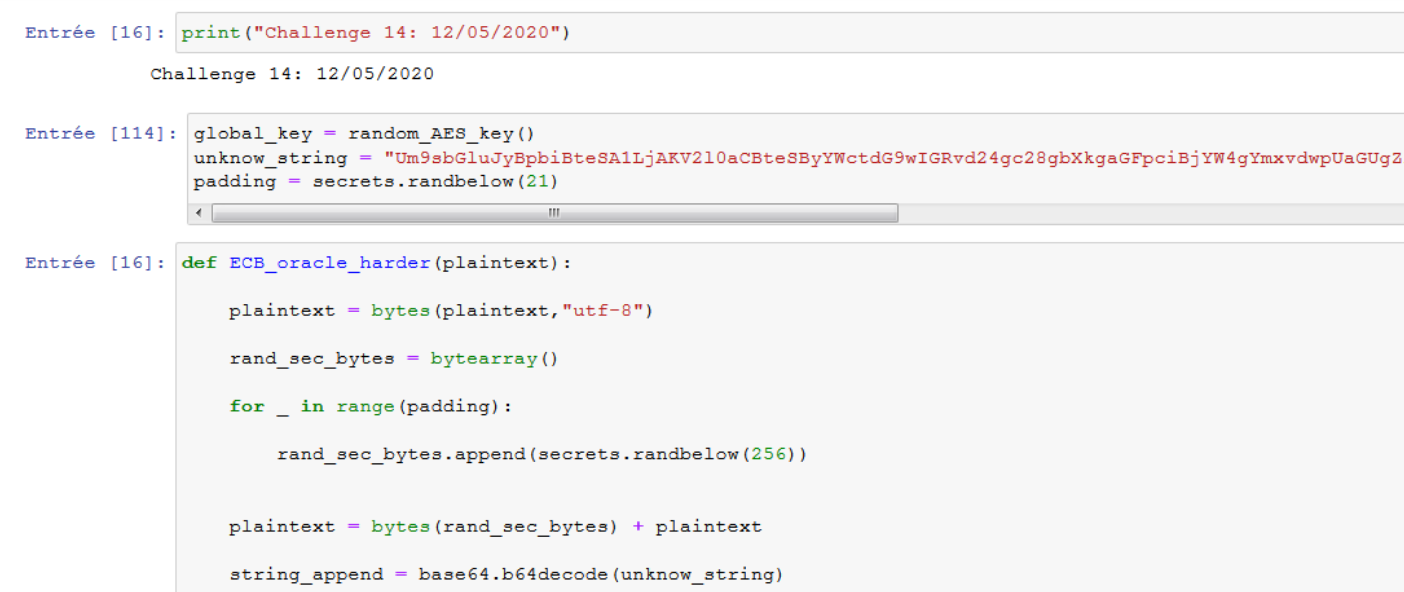
def ECB_oracle(plaintext):
plaintext = bytes(plaintext,"utf-8")
string_append = base64.b64decode(unknow_string)
plaintext = plaintext + string_append
return AES_ECB_mode_encrypt(plaintext,global_key)La notion d’oracle est présente à de nombreuses reprises lors des challenges, et permet de simuler un côté “serveur”. Même si nous connaissons les détails de la fonction, notamment la taille de bloc et l’algorithme de chiffrement utilisé, le challenge pousse à identifier ces caractéristiques.
La taille du bloc peut être déduite en chiffrant un texte contenant n fois le même caractère, en incrémentant n et en observant les différences entre les textes chiffrés. L’algorithme, et surtout son mode, peut être déduit en cherchant à détecter le mode ECB (Electronic Code Block) sur le texte chiffré. En ayant la taille de bloc B, il suffit de chiffrer un texte contenant 2B fois le même caractère, et d’observer si une répétition apparaît dans le texte chiffré.
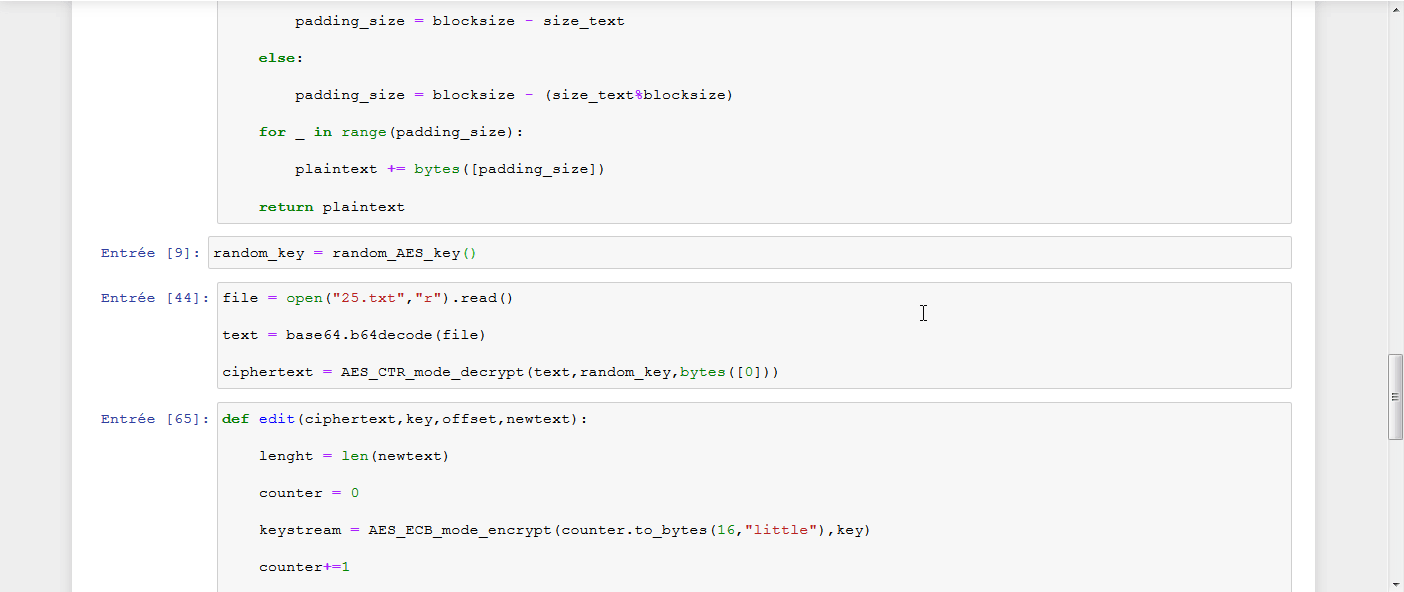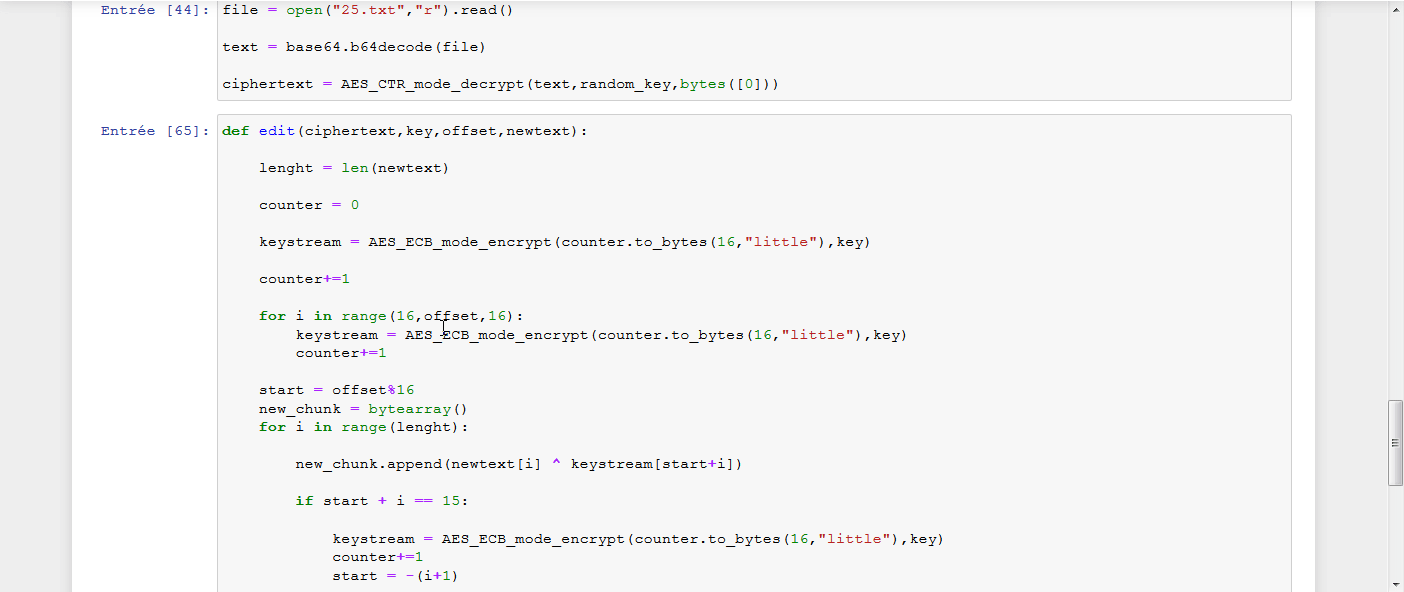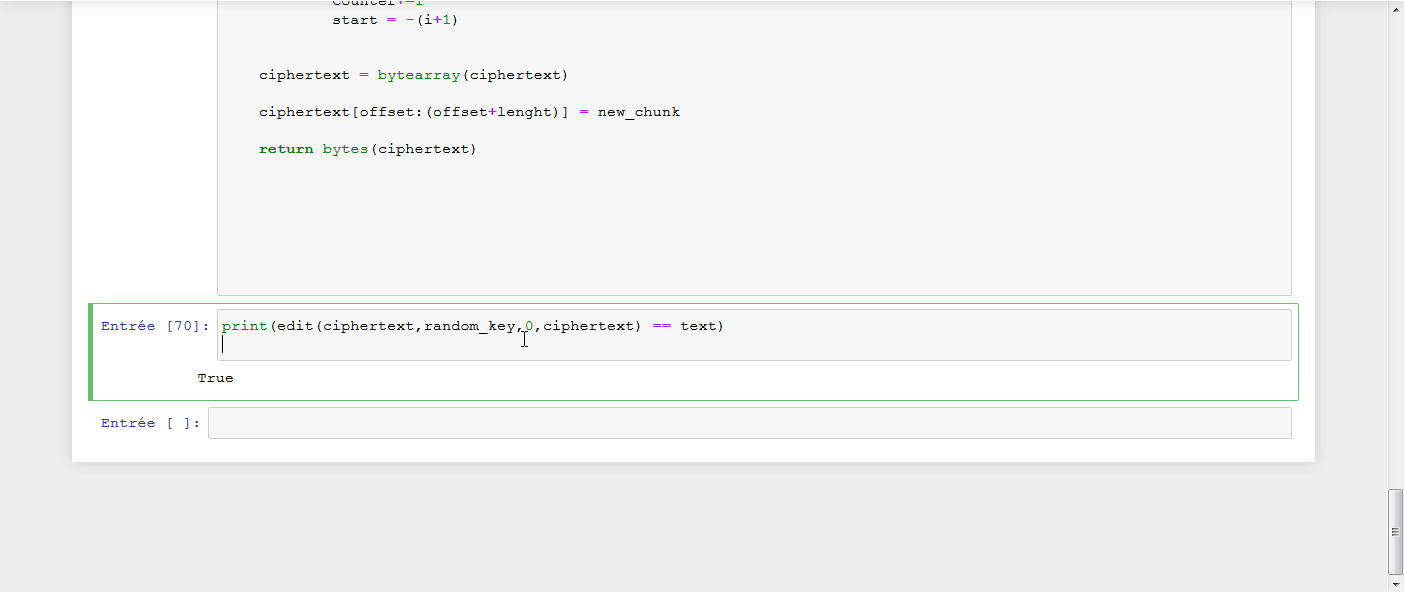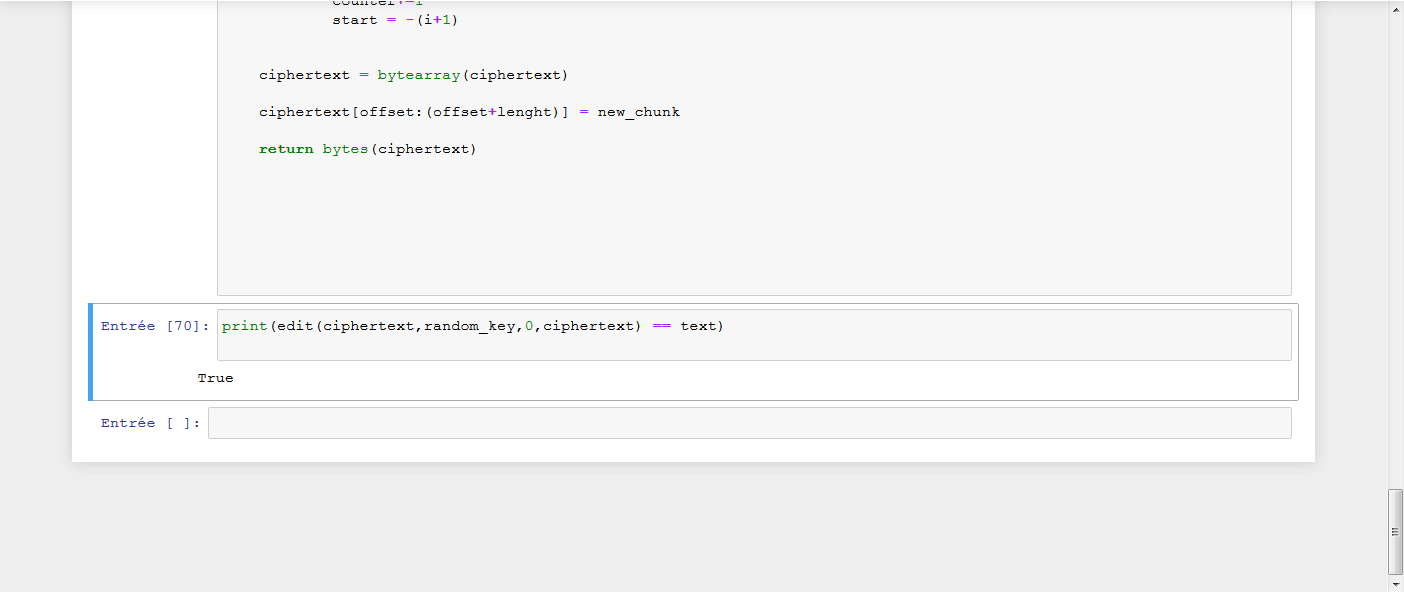
Toutes ces informations connues, le but était de déchiffrer la chaîne unknow_string ajoutée après le plaintext fourni par l’utilisateur, en devinant octet par octet cette chaîne. Pour voir ma solution, il faut chercher le challenge 12 dans le Set 2.